
Efficient, Reliable, and Faster Data – A Hierarchical & Modular Approach
By Victor Bagwell, Associate Chief of Information Science, Hackensack Meridian Health
Advancements and increased availability of real-time data, medical imaging, and big data analytics has created a rapid increase in healthcare data volume. In parallel, there is more demand for access to the data and applications leveraging more sophisticated business intelligence, data science, and artificial intelligence (AI). At each hospital, this demand includes the need for clinical, hospital claims, patient behavior and sentiment, social determinants of health, R&D, regional, national public health, and other data. Analysts, data miners, data scientists, researchers, and others are demanding more data and at an accelerated pace.
The Problem
Collecting data is not enough. The data must be put in a form that can be utilized. To do this, data must be processed, normalized, cleaned, aggregated, and prepared so it can be used effectively. Regrettably, different applications store their data architectures, database systems, and there are myriad standards and interoperability issues with which to contend. Ultimately, the heavy lifting of data and managing the data pipeline (Figure 1) is the job of data integration teams that build data warehouses and operational data stores. The data integration is at the heart of the issue. It is a complex process that requires standardized data architectures and the development of extract, transform, load (ETL) code to move and modify the data to conform to the architectures.
Figure 1

Further, data integration requires the management of changing data sources, end-user requirements, access, and business needs. This involves thousands of ETL jobs and hundreds of terabytes of data. Consideration must be given to the order that data is processed, loads on the system infrastructure (e.g., CPU, memory, disc I/O, storage), and the time when data needs to be refreshed and available to end-users. The time and resources to achieve successful data integration can be risky, challenging, and costly. How can the data be delivered in a safe, secure, reliable, scalable, timely, and cost-effective way?
Traditional Approach
The traditional method is to create ETL code to handle each work request. Sometimes code is copied from a prior similar request to accelerate the development of the new request. The ETL is then tested and scheduled. Any time a change is required, the entire code needs to be re-tested (front-to-back). Any time a data source is changed, “all” of the ETL code that uses that data source must be modified and tested, one by one, until all of them are verified. This method is inefficient, requires enormous resources, and does not provide scalability. Because of its complexity, such code, over time, is difficult to understand. Even with documentation, there is a risk that changing code will produce unforeseen effects.
The Solution: Hierarchal & Modular Approach
In search of a solution, a modular approach was considered where the data pipeline is designed with different ETL modules that are isolated and work independently. In some ways, this is analogous to an object-oriented or microservices-based system architecture. By isolating the ETL functionality into hierarchical and modular components, master ETL jobs simply re-use existing ETLs from the master library without redeveloping and testing them. New ETL can be added, reviewed, and considered for inclusion in the hierarchical modular library. When changes are needed, only the affected ETLs need to be changed. By leveraging the hierarchical and modular approach, centralized core ETL modules help ensure a single source of data truth available to the enterprise.
Examples of modular ETL library functions are de-duplication, patient demographic, diagnosis, procedure, lab, and admission/discharge/transfer (ADT).
Figure 2
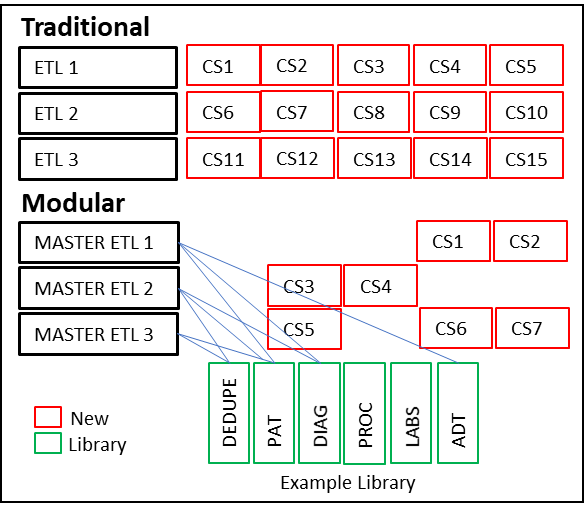
Figure 2 compares the traditional method of creating non-modular ETLs to modular ones. The red boxes indicate the new ETL development work required. The green boxes represent existing library ETL modules. The modular example shows that the MASTER ETL leverages the existing library and only adds ETL code segment (CS) where they do not already exist in the library. In this hypothetical example, the traditional method requires 15 code segments, and the modular requires only 7. Generalizing, the modular approach reduces the work by over 53%.
We mapped the function of new and legacy ETL code (core, primary, secondary, etc.) that already existed in the environment through team collaboration and investigation. Many of the functions were easily grouped into hierarchies based on their function and logical processing position in the data pipeline. Next, we looked “within” each ETL and found cases where complex coding was heavily duplicated across many ETLs. We communicated with end-users and coders and deconstructed these into their root/component functional parts. Each ETL code segment was then added to its appropriate hierarchy based on its function. This was a large project. By working with end-users, we prioritized which ETLs were most important and targeted them first. In this way, we provided operational relief to those areas as quickly as possible.
Benefits
In practice, utilizing the hierarchical and modular ETL model resulted in a recognized 45% decrease in time to delivery and FTE labor. Further, due to a reduction in duplicate storage, the overall required disc storage decreased 30%. Future modifications to the new ETL code will only require the centralized library module to be modified and tested. This will result in future savings by avoiding extensive across-the-board code modifications and retesting. During the pandemic, the ability to accommodate changes quickly is an important win. Over time, as the ETL hierarchical module library increases in size, the need for additional modules will decrease. This will provide additional future efficiencies and return on investment.
What we learned
Collaboration, communication, taking a step back to take a leap forward, build on a solid, scalable, and extensible foundation were all important components of obtaining the solution. Optimization is key. When possible, avoid redundant development, testing, and storage. Look at the systems from a heuristic perspective. Spend a little more time the first time around to do it right and avoid having to refactor and/or invest much more time to modify or scale up later.


